基于Python网络爬虫的电子产品信息查询与可视化系统设计
引言
在信息爆炸的时代,电子产品种类繁多,更新迭代迅速,消费者在选购时往往面临信息过载、价格波动、参数对比困难等问题。传统的比价和信息查询方式效率低下,难以满足用户对实时、全面、直观信息的需求。因此,开发一个基于Python网络爬虫的电子产品信息查询可视化系统,能够自动化地从各大电商平台和科技媒体抓取数据,并通过直观的图表进行展示,具有重要的现实意义和应用价值。
系统架构与核心技术
本系统主要分为三大核心模块:数据采集模块、数据处理与存储模块、以及信息可视化与查询模块。\n
1. 数据采集模块
该模块是系统的基石,负责从目标网站(如京东、天猫、中关村在线等)自动抓取电子产品信息。我们主要使用Python的requests库或Scrapy框架来模拟浏览器发送HTTP请求,获取网页HTML内容。利用BeautifulSoup或lxml等解析库,根据网页结构(DOM树)定位并提取关键信息,如产品名称、品牌、型号、价格、详细规格参数(CPU、内存、屏幕尺寸等)、用户评价、评分以及发布时间等。为了应对网站的反爬虫机制(如IP封锁、请求频率限制),系统需集成代理IP池、设置合理的请求间隔(time.sleep)和伪装请求头(User-Agent)等策略,确保数据采集的稳定性和合法性。
2. 数据处理与存储模块
原始爬取的数据通常是杂乱无章的,包含大量冗余或格式不一致的信息。因此,本模块首先对数据进行清洗,包括去除HTML标签、处理缺失值、统一数值和单位格式(例如,将“8GB”统一为“8 GB”)、中文文本分词(用于后续分析)等。清洗后的结构化数据将被存储起来,以供查询和分析。根据数据量和查询需求,可以选择轻量级的SQLite数据库、MySQL数据库,或者非关系型的MongoDB。数据库设计需合理规划表结构,例如建立产品信息表、价格历史表、用户评价表等,并建立索引以优化查询速度。
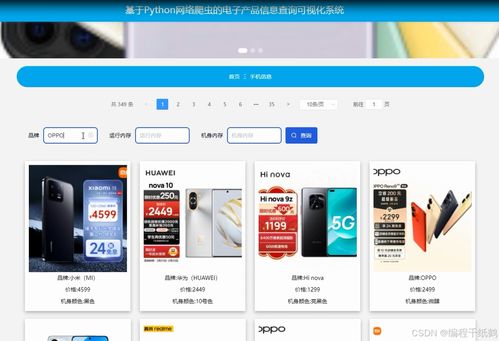
3. 信息可视化与查询模块
这是系统与用户交互的窗口,旨在将枯燥的数据转化为直观的洞察。前端可以使用Flask或Django这类Python Web框架快速搭建,也可以结合ECharts、Pyecharts或Plotly等可视化库来生成丰富的交互式图表。核心功能包括:
- 智能查询:用户可以通过产品名称、品牌、价格区间、关键参数(如“CPU型号=i7”)进行组合搜索。
- 价格趋势分析:对特定产品绘制其历史价格曲线图,帮助用户判断最佳购买时机。
- 参数对比:以雷达图、表格或多维度条形图的形式,并列展示2-3款竞争产品的核心参数,优劣一目了然。
- 市场分布洞察:使用饼图或柱状图展示不同品牌在某个品类(如手机)中的市场份额,或不同价格区间的产品数量分布。
- 口碑评价分析:通过对用户评论进行情感分析(可使用
SnowNLP或Jieba+情感词典),生成情感倾向分布图(正面/中性/负面),并提取高频关键词形成词云图。
系统优势与应用场景
优势:
1. 自动化与实时性:系统定时自动运行爬虫任务,确保信息的时效性。
2. 信息整合能力强:打破信息孤岛,将分散在各个平台的数据汇集一处。
3. 决策支持可视化:将复杂数据图形化,极大降低了信息理解门槛,辅助用户做出更明智的购买决策。
4. 可扩展性高:通过修改爬虫解析规则,可以轻松扩展至新的数据源或产品品类。
应用场景:
- 个人消费者:用于购物前的深度调研和比价。
- 电子产品爱好者与评测者:快速追踪市场动态和产品迭代信息。
- 市场分析师:进行行业趋势分析、竞品监控和价格策略研究。
- 小型零售商:监控渠道价格,制定采购和定价策略。
挑战与展望
开发此类系统也面临一些挑战:网站结构变动会导致爬虫失效,需要持续维护;大规模爬取需平衡效率与对目标网站的压力;用户隐私和数据安全需严格遵守相关法律法规。
可以引入更智能的技术,如利用机器学习模型预测价格走势、自动识别产品图片中的参数信息,或构建个性化的产品推荐子系统。开发移动端应用或微信小程序,将使系统更加便捷易用。
###
基于Python网络爬虫的电子产品信息查询可视化系统,通过高效的数据采集、智能的数据处理与生动的可视化呈现,构建了一个强大的信息咨询工具。它不仅提升了用户获取和消化信息的效率,更以数据驱动的方式,为电子产品的选购和市场分析提供了深度价值,是Python技术在解决实际生活问题中的一个典型而成功的应用案例。
如若转载,请注明出处:http://www.yuedutiandi.com/product/45.html
更新时间:2026-06-18 02:19:36